
Post:KMP
一·算法简介
1.简介:一种高效字符串匹配算法,通过预处理模式串生成next数组(部分匹配表),在匹配失败时跳过无效比较,将时间复杂度优化至O(n+m)(n为主串长度,m为模式串长度)
2.next数组
- 定义:next[i]表示模式串P[0..i]中,最长相等真前缀和真后缀的长度(不包括子串本身)
- 作用:当匹配失败时,根据next值移动模式串指针,避免主串回溯
- 构建逻辑
- P[0]:无前缀/后缀,next[0]=0
- P[1..8]:若P[i] == P[j],则j++;否则j = next[j-1]回退
二·经典例题
1.
P3375 【模板】KMP
题目描述
给出两个字符串 $s_1$ 和 $s_2$,若 $s_1$ 的区间 $[l, r]$ 子串与 $s_2$ 完全相同,则称 $s_2$ 在 $s_1$ 中出现了,其出现位置为 $l$。
现在请你求出 $s_2$ 在 $s_1$ 中所有出现的位置。
定义一个字符串 $s$ 的 border 为 $s$ 的一个非 $s$ 本身的子串 $t$,满足 $t$ 既是 $s$ 的前缀,又是 $s$ 的后缀。
对于 $s_2$,你还需要求出对于其每个前缀 $s’$ 的最长 border $t’$ 的长度。
输入格式
第一行为一个字符串,即为 $s_1$。
第二行为一个字符串,即为 $s_2$。
输出格式
首先输出若干行,每行一个整数,按从小到大的顺序输出 $s_2$ 在 $s_1$ 中出现的位置。
最后一行输出 $|s_2|$ 个整数,第 $i$ 个整数表示 $s_2$ 的长度为 $i$ 的前缀的最长 border 长度。
输入输出样例 #1
输入 #1
ABABABC
ABA
输出 #1
1
3
0 0 1
说明/提示
样例 1 解释
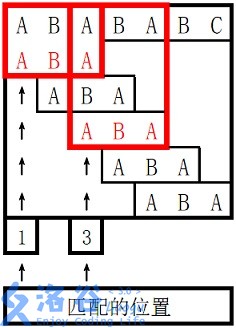 。
。
对于 $s_2$ 长度为 $3$ 的前缀 ABA,字符串 A 既是其后缀也是其前缀,且是最长的,因此最长 border 长度为 $1$。
数据规模与约定
本题采用多测试点捆绑测试,共有 3 个子任务。
-
Subtask 0(30 points):$ s_1 \leq 15$,$ s_2 \leq 5$。 -
Subtask 1(40 points):$ s_1 \leq 10^4$,$ s_2 \leq 10^2$。 - Subtask 2(30 points):无特殊约定。
- Subtask 3(0 points):Hack。
| 对于全部的测试点,保证 $1 \leq | s_1 | , | s_2 | \leq 10^6$,$s_1, s_2$ 中均只含大写英文字母。 |
解:
#include<iostream>
#include<vector>
using namespace std;
vector<int> buildnext(const string& p) {
vector<int> next(p.length(), 0); // 初始化 next 数组,长度与 p 相同,初始值全为 0
int len = 0; // 当前最长公共前后缀长度(即 border 长度)
int i = 1; // 从模式串的第 2 个字符开始遍历(下标从 1 开始)
while (i < p.length()) { // 遍历模式串 p
if (p[i] == p[len]) { // 当前字符匹配成功(扩展 border)
len++; // border 长度 +1
next[i] = len; // 记录当前位置的 border 长度
i++; // 继续处理下一个字符
}
else { // 当前字符匹配失败
if (len != 0) { // 若已有部分匹配,则回溯到前一个 border 位置
len = next[len - 1]; // 关键:利用已计算的 next 值回溯(避免重复匹配)
}
else { // 无匹配部分(border 长度为 0)
next[i] = 0; // 当前无 border,记录为 0
i++; // 继续处理下一个字符
}
}
}
return next; // 返回构建好的 next 数组
}
vector<int> kmpsearch(const string& t, const string& p) {
if (p.empty()) return {}; // 边界处理:模式串为空时直接返回
vector<int> position; // 存储所有匹配的起始位置
vector<int> next = buildnext(p); // 获取模式串 p 的 next 数组
int i = 0, j = 0; // i 遍历文本串 t,j 遍历模式串 p
while (i < t.size()) { // 遍历文本串
if (j < p.size() && t[i] == p[j]) { // 当前字符匹配成功
i++;
j++;
}
if (j == p.size()) { // 完整匹配到模式串
position.push_back(i - j); // 记录匹配位置的起始索引(0-based)
if (j > 0) j = next[j - 1]; // 回溯 j 以支持重叠匹配(如 "AAAA" 中找 "AAA")
else j = 0; // 边界:模式串长度为 1 时避免越界
}
else if (i < t.size() && t[i] != p[j]) { // 当前字符匹配失败
if (j > 0) j = next[j - 1]; // 回溯 j 到前一个 border 位置
else i++; // 模式串已回溯到起点,移动文本串指针
}
}
return position; // 返回所有匹配位置
}
int main() {
string t, p;
cin >> t >> p;
vector<int> position = kmpsearch(t, p);
vector<int> next = buildnext(p);
for (int& i : position) {
cout << i + 1 << endl;
}
if (!next.empty()) {
cout << next[0];
for (int i = 1; i < next.size(); i++) {
cout << " " << next[i];
}
}
return 0;
}
【评】此题为最基础的模板题(然而还是比较抽象),结合视频食用更佳😋
2.
0408 前缀中的周期
题目描述
一个字符串的前缀是从第一个字符开始的连续若干个字符,例如”abaab”共有5个前缀,分别是a, ab, aba, abaa, abaab。
我们希望知道一个N位字符串S的前缀是否具有循环节。换言之,对于每一个从头开始的长度为 i (i 大于1)的前缀,是否由重复出现的子串A组成,即 AAA…A (A重复出现K次,K 大于 1)。如果存在,请找出最短的循环节对应的K值(也就是这个前缀串的所有可能重复节中,最大的K值)。
输入格式
输入包括多组测试数据。每组测试数据包括两行。 第一行包括字符串S的长度N(2 <= N <= 1 000 000)。 第二行包括字符串S。 输入数据以只包括一个0的行作为结尾。
输出格式
对于每组测试数据,第一行输出 “Test case #“ 和测试数据的编号。 接下来的每一行,输出前缀长度i和重复测数K,中间用一个空格隔开。前缀长度需要升序排列。 在每组测试数据的最后输出一个空行。
输入输出样例 #1
输入 #1
3
aaa
12
aabaabaabaab
0
输出 #1
Test case #1
2 2
3 3
Test case #2
2 2
6 2
9 3
12 4
解:
#include<iostream>
#include<vector>
using namespace std;
vector<int> buildnext(string s) {
if (s.empty()) return {};
vector<int> next(s.length(), 0);
int len = 0;
int i = 1;
while (i < s.length()) {
if (s[i] == s[len]) {
len++;
next[i] = len;
i++;
}
else {
if (len != 0) {
len = next[len - 1];
}
else {
next[i] = 0;
i++;
}
}
}
return next;
}
int main() {
int len;
int num = 1;
string s;
while (cin >> len) {
if (len == 0)
break;
cin >> s;
cout << "Test case #" << num << endl;
num++;
vector<int> next = buildnext(s);
for (int i = 1; i < s.length(); i++) {
if (next[i] != 0) {
int cyclelen = i + 1 - next[i];
if ((i + 1) % cyclelen == 0) {
int I = i + 1;
int K = I / cyclelen;
cout << I << " " << K << endl;
}
}
}
cout << endl;
}
return 0;
}
【评】循环节长度公式的原理:最小循环节长度 = 子串总长度 - 最长公共前后缀长度(确认循环节存在:验证子串长度能被循环节长度整除(确保完整重复))想清楚这一点,看似复杂的题目便迎刃而解💕
Comments